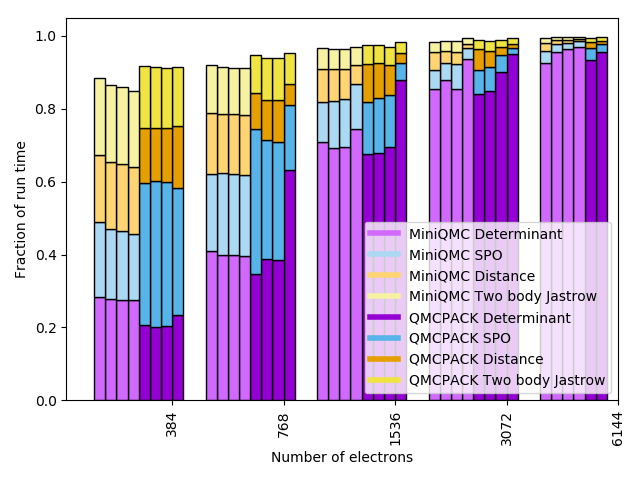
MiniQMC comprises all of the key kernels that are in QMCPACK, although their relative importance in terms of percentage of total execution time is slightly different. MiniQMC implements one walker per MPI rank, but has no inter-rank communication—it is meant for single-node explorations only. Conversely, QMCPACK is fully MPI parallelized and is designed to take advantage of large-scale systems. Both miniQMC and QMCPACK support OpenMP threads, where the number of threads for a DMC calculation should be chosen to be only slightly larger than the number of walkers according to QMCPACK documentation. However, from the miniQMC page and our own trials, as shown in the figure below, performance is not largely sensitive to an increase in the number of threads. Therefore, to compare the proxy to the parent, we chose a single-node configuration, with one OpenMP thread per MPI rank; we chose the number MPI ranks based on the available socket memory as explained below.
The exascale challenge problem for QMCPACK is to simulate transition metal oxide systems of approximately 1000 atoms to 10~meV statistical accuracy with performance portability. The transition oxide of choice is nickel oxide (NiO), and the target number of atoms is 1024. The 1024 atom problem is extremely memory intensive and cannot practically be executed on any contemporary systems without running out of memory. We chose a fairly large, contemporary testbed system at Sandia for performance measurement and the largest problem that we can execute on this system (192GB/node memory) is 256 atoms (3072 electrons), which uses about 12GB per core. The system we ran on has 24 cores per socket, two sockets per node, but we use only 4 cores per socket (48GB) in order to force a reasonable run time and to ensure we execute within memory limits.
For QMCPACK, we use an input file that was obtained from the development team. To match this input for miniQMC, we use the -g 2 2 2 flag, which according to the table listed in the miniQMC page, is 256 atoms and 3072 electrons. We also use the -r 0.999 flag to more accurately reproduce a DMC run. MiniQMC is designed to execute one walker per rank on a single node. For comparison of miniQMC and QMCPACK, we use 8 ranks on a single node.