From Website:
miniGMG is a compact benchmark for understanding the performance challenges associated with geometric multigrid solvers found in applications built from AMR MG frameworks like CHOMBO or BoxLib when running on modern multi- and manycore-based supercomputers. It includes both productive reference examples as well as highly-optimized implementations for CPUs and GPUs. It is sufficiently general that it has been used to evaluate a broad range of research topics including PGAS programming models and algorithmic tradeoffs inherit in multigrid.
Note, miniGMG code has been supersceded by HPGMG.
Problem Size and Run Configuration
./run.miniGMG log2BoxSize \
[BoxesPerProcess_i BoxesPerProcess_j BoxesPerProcess_k] \
[Processes_i Processes_j Processes_k]
log2BoxSize = 6 is a good proxy for real applications
Analysis
Build and Run Information
Compiler = icpc (ICC) 18.0.1 20171018
Build Flags = -g -O3 -march=native
Run Parameters = 8 2 2 2 1 1 1
Scaling
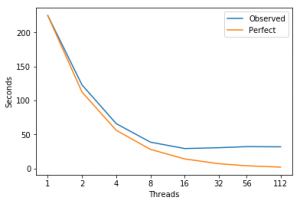
Intel Software Development Emulator
| SDE Metrics | |
|---|---|
| Arithmetic Intensity | 0.13 |
| Bytes per Load Inst | 17.94 |
| Bytes per Store Inst | 9.31 |
| FLOPS per Inst | 1.19 |
Roofline – Intel(R) Xeon(R) Platinum 8180M CPU
112 Threads – 56 – Cores 3200.0 Mhz
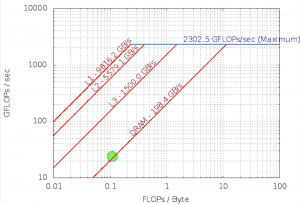
Experiment Aggregate Metrics
| 1 (100.0%) | 0.78 | 0.39 | 0.33 | 20.64% | 51.89% | 79.55% | 3.91% | 9.03% | 0.65% |
| 112 (100.0%) | 0.71 | 0.14 | 0.08 | 17.80% | 51.04% | 89.96% | 3.36% | 0.00% | 1.56% |
Jacobi
9 void smooth(domain_type * domain, int level, int phi_id,
int rhs_id, double a, double b){
10 if(numSmooths&1){
11 printf("error - numSmooths must be even...\n");
12 exit(0);
13 }
14
15 int CollaborativeThreadingBoxSize = 100000; // i.e. never
16 #ifdef __COLLABORATIVE_THREADING
17 CollaborativeThreadingBoxSize = 1 << __COLLABORATIVE_THREADING;
18 #endif
19 int omp_across_boxes = (domain->subdomains[0].levels[level].dim.i
< CollaborativeThreadingBoxSize);
20 int omp_within_a_box = (domain->subdomains[0].levels[level].dim.i
>= CollaborativeThreadingBoxSize);
21
22 int box,s;
23 int ghosts = domain->ghosts;
24 double TwoThirds = 2.0/3.0;
25
26 // if communication-avoiding, need RHS for stencils in ghost zones
27 if(ghosts>1)exchange_boundary(domain,level,rhs_id,1,1,1);
28
29 for(s=0;s<numSmooths;s+=ghosts){
30 // Jacobi ping pongs between phi and __temp
// corners/edges if doing communication-avoiding...
31 if((s&1)==0)exchange_boundary(domain,level,phi_id,1,ghosts>1,ghosts>1);
// corners/edges if doing communication-avoiding...
32 else exchange_boundary(domain,level,__temp,1,ghosts>1,ghosts>1);
33
34 // now do ghosts communication-avoiding smooths on each box...
35 uint64_t _timeStart = CycleTime();
36
37 #pragma omp parallel for private(box) if(omp_across_boxes)
38 for(box=0;box<domain->subdomains_per_rank;box++){
39 int i,j,k,ss;
40 int pencil = domain->subdomains[box].levels[level].pencil;
41 int plane = domain->subdomains[box].levels[level].plane;
42 int ghosts = domain->subdomains[box].levels[level].ghosts;
43 int dim_k = domain->subdomains[box].levels[level].dim.k;
44 int dim_j = domain->subdomains[box].levels[level].dim.j;
45 int dim_i = domain->subdomains[box].levels[level].dim.i;
46 double h2inv = 1.0/(domain->h[level]*domain->h[level]);
47 double * __restrict__ rhs = domain->
subdomains[box].levels[level].grids[ rhs_id] + ghosts*(1+pencil+plane);
48 double * __restrict__ alpha = domain->
subdomains[box].levels[level].grids[__alpha ] + ghosts*(1+pencil+plane);
49 double * __restrict__ beta_i = domain->
subdomains[box].levels[level].grids[__beta_i] + ghosts*(1+pencil+plane);
50 double * __restrict__ beta_j = domain->
subdomains[box].levels[level].grids[__beta_j] + ghosts*(1+pencil+plane);
51 double * __restrict__ beta_k = domain->
subdomains[box].levels[level].grids[__beta_k] + ghosts*(1+pencil+plane);
52 double * __restrict__ lambda = domain->
subdomains[box].levels[level].grids[__lambda] + ghosts*(1+pencil+plane);
53
54 int ghostsToOperateOn=ghosts-1;
55 for(ss=s;ss<s+ghosts;ss++,ghostsToOperateOn--){
56 double * __restrict__ phi;
57 double * __restrict__ phi_new;
58 if((ss&1)==0){phi = domain->subdomains[box].levels[level].grids[phi_id]
+ ghosts*(1+pencil+plane);
59 phi_new= domain->subdomains[box].levels[level].grids[__temp]
+ ghosts*(1+pencil+plane);}
60 else{phi = domain->subdomains[box].levels[level].grids[__temp]
+ ghosts*(1+pencil+plane);
61 phi_new= domain->subdomains[box].levels[level].grids[phi_id]
+ ghosts*(1+pencil+plane);}
| 1 (68.7%) | 0.75 | 0.42 | 0.35 | 21.50% | 50.89% | 71.19% | 4.30% | 9.87% | 0.31% |
| 112 (50.2) | 0.33 | 0.08 | 0.02 | 48.36% | 50.61% | 90.37% | 4.30% | 0.00% | 1.68% |
62 #pragma omp parallel for private(k,j,i) if(omp_within_a_box) collapse(2)
63 for(k=0-ghostsToOperateOn;k<dim_k+ghostsToOperateOn;k++){
64 for(j=0-ghostsToOperateOn;j<dim_j+ghostsToOperateOn;j++){
65 for(i=0-ghostsToOperateOn;i<dim_i+ghostsToOperateOn;i++){
66 int ijk = i + j*pencil + k*plane;
67 double helmholtz = a*alpha[ijk]*phi[ijk]
68 -b*h2inv*(
69 beta_i[ijk+1 ]*( phi[ijk+1 ]-phi[ijk ] )
70 -beta_i[ijk ]*( phi[ijk ]-phi[ijk-1 ] )
71 +beta_j[ijk+pencil]*( phi[ijk+pencil]-phi[ijk ] )
72 -beta_j[ijk ]*( phi[ijk ]-phi[ijk-pencil] )
73 +beta_k[ijk+plane ]*( phi[ijk+plane ]-phi[ijk ] )
74 -beta_k[ijk ]*( phi[ijk ]-phi[ijk-plane ] )
75 );
76 phi_new[ijk] = phi[ijk] - TwoThirds*lambda[ijk]*(helmholtz-rhs[ijk]);
77 }}}
78 } // ss-loop
79 } // box-loop
80 domain->cycles.smooth[level] += (uint64_t)(CycleTime()-_timeStart);
81 } // s-loop
82 }
Residual
9 void residual(domain_type * domain, int level, int res_id, int phi_id,
int rhs_id, double a, double b){
10 // exchange the boundary for x in prep for Ax...
11 // for 7-point stencil, only needs to be a 1-deep ghost zone & faces only
12 exchange_boundary(domain,level,phi_id,1,0,0);
13
14 // now do residual/restriction proper...
15 uint64_t _timeStart = CycleTime();
16 int CollaborativeThreadingBoxSize = 100000; // i.e. never
17 #ifdef __COLLABORATIVE_THREADING
18 CollaborativeThreadingBoxSize = 1 << __COLLABORATIVE_THREADING;
19 #endif
20 int omp_across_boxes = (domain->subdomains[0].levels[level].dim.i < CollaborativeThreadingBoxSize);
21 int omp_within_a_box = (domain->subdomains[0].levels[level].dim.i >= CollaborativeThreadingBoxSize);
22 int box;
23
24 #pragma omp parallel for private(box) if(omp_across_boxes)
25 for(box=0;box<domain->subdomains_per_rank;box++){
26 int i,j,k;
27 int pencil = domain->subdomains[box].levels[level].pencil;
28 int plane = domain->subdomains[box].levels[level].plane;
29 int ghosts = domain->subdomains[box].levels[level].ghosts;
30 int dim_k = domain->subdomains[box].levels[level].dim.k;
31 int dim_j = domain->subdomains[box].levels[level].dim.j;
32 int dim_i = domain->subdomains[box].levels[level].dim.i;
33 double h2inv = 1.0/(domain->h[level]*domain->h[level]);
// i.e. [0] = first non ghost zone point
34 double * __restrict__ phi = domain->subdomains[box].levels[level].grids[ phi_id]
+ ghosts*(1+pencil+plane);
35 double * __restrict__ rhs = domain->subdomains[box].levels[level].grids[ rhs_id]
+ ghosts*(1+pencil+plane);
36 double * __restrict__ alpha = domain->subdomains[box].levels[level].grids[__alpha ]
+ ghosts*(1+pencil+plane);
37 double * __restrict__ beta_i = domain->subdomains[box].levels[level].grids[__beta_i]
+ ghosts*(1+pencil+plane);
38 double * __restrict__ beta_j = domain->subdomains[box].levels[level].grids[__beta_j]
+ ghosts*(1+pencil+plane);
39 double * __restrict__ beta_k = domain->subdomains[box].levels[level].grids[__beta_k]
+ ghosts*(1+pencil+plane);
40 double * __restrict__ res = domain->subdomains[box].levels[level].grids[ res_id]
+ ghosts*(1+pencil+plane);
41
| 1 (14.3%) | 0.85 | 0.42 | 0.34 | 21.93% | 51.41% | 68.72% | 4.39% | 10.03% | 0.34% |
| 112 (10.7%) | 0.35 | 0.08 | 0.02 | 49.80% | 50.00% | 90.58% | 4.24% | 0.00% | 1.71% |
42 #pragma omp parallel for private(k,j,i) if(omp_within_a_box) collapse(2)
43 for(k=0;k<dim_k;k++){
44 for(j=0;j<dim_j;j++){
45 for(i=0;i<dim_i;i++){
46 int ijk = i + j*pencil + k*plane;
47 double helmholtz = a*alpha[ijk]*phi[ijk]
48 -b*h2inv*(
49 beta_i[ijk+1 ]*( phi[ijk+1 ]-phi[ijk ] )
50 -beta_i[ijk ]*( phi[ijk ]-phi[ijk-1 ] )
51 +beta_j[ijk+pencil]*( phi[ijk+pencil]-phi[ijk ] )
52 -beta_j[ijk ]*( phi[ijk ]-phi[ijk-pencil] )
53 +beta_k[ijk+plane ]*( phi[ijk+plane ]-phi[ijk ] )
54 -beta_k[ijk ]*( phi[ijk ]-phi[ijk-plane ] )
55 );
56 res[ijk] = rhs[ijk]-helmholtz;
57 }}}
58 }
59 domain->cycles.residual[level] += (uint64_t)(CycleTime()-_timeStart);
60 }