A simple conjugate gradient benchmark code for a 3D chimney domain on an arbitrary number of processors.
Problem Size Discussion
From the application README
Suggested: Data size is over a range from 25% of total system memory up to 75%.
With nx=ny=nz and n = nx * ny * nz
Total memory per MPI rank: 720 * n bytes for 27 pt stencil, 240 * n bytes for 7 pt stencil.
Additional details in application README
Analysis
On the Skylake machine on which it was analyzed, HPCCG uses 70-80% of the DRAM bandwidth despite having memory latency issues due to a indirect memory access.
Parameters
Compiler = icc (ICC) 18.0.1 20171018
Build_Flags = -g -O3 -march=native -ftree-vectorize -qopenmp -DUSING_OMP
Run_Parameters = 256 256 256
Scaling
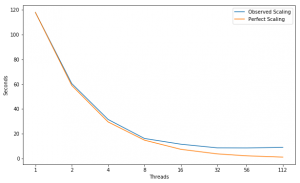
Performance Improvement
| Threads | |||||||
|---|---|---|---|---|---|---|---|
| Speed Up | 1.95X | 1.92X | 1.95X | 1.40X | 1.34X | 1.01X | 0.95X |
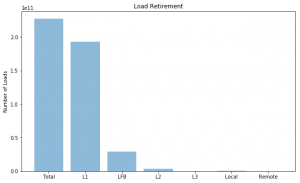
Hit Locations
FLOPS
| Double Precision | ||||||
|---|---|---|---|---|---|---|
| PMU | 3.520e+10 | 6.790e+10 | 2.550e+09 | 0.000e+00 | 1.812e+11 | 2.136e+01 |
| SDE | 3.500e+10 | 6.748e+10 | 2.525e+09 | 0.000e+00 | 1.801e+11 | 2.123e+01 |
Intel Software Development Emulator
| Intel SDE | |
|---|---|
| Arithmetric Intensity | 0.103 |
| FLOPS per Inst | 0.442 |
| FLOPS per FP Inst | 1.71 |
| Bytes per Load Inst | 7.96 |
| Bytes per Store Inst | 7.52 |
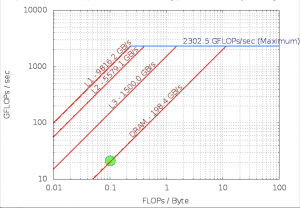
Roofline – Intel(R) Xeon(R) Platinum 8180M CPU
112 Threads – 56 – Cores 3200.0 Mhz
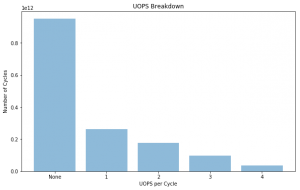
UOPS Executed
Experiment Aggregate Metrics
| 1 (100.0%) | 1.35 | 0.70 | 0.59 | 2.44% | 43.36% | 91.79% | 11.18% | 38.09% | 42.03% |
| 56 (100.0%) | 0.42 | 0.20 | 0.17 | 2.04% | 44.08% | 91.52% | 2.71% | 24.03% | 65.88% |
| 112 (100.0%) | 0.46 | 0.12 | 0.10 | 2.12% | 43.94% | 85.94% | 2.73% | 22.06% | 59.98% |
HPC_sparsemv.cpp
| 1 (83.1%) | 1.39 | 0.77 | 0.68 | 1.86% | 42.24% | 72.59% | 11.36% | 38.16% | 42.23% |
| 56 (70.4%) | 0.47 | 0.25 | 0.22 | 1.74% | 42.51% | 68.42% | 3.27% | 28.55% | 78.07% |
| 112 (65.5%) | 0.48 | 0.13 | 0.12 | 2.19% | 42.56% | 75.15% | 3.51% | 28.05% | 76.01% |
66 int HPC_sparsemv( HPC_Sparse_Matrix *A,
67 const double * const x, double * const y)
68 {
69
70 const int nrow = (const int) A->local_nrow;
71
72 #ifdef USING_OMP
73 #pragma omp parallel for
74 #endif
75 for (int i=0; i< nrow; i++)
76 {
77 double sum = 0.0;
78 const double * const cur_vals =
79 (const double * const) A->ptr_to_vals_in_row[i];
80
81 const int * const cur_inds =
82 (const int * const) A->ptr_to_inds_in_row[i];
83
84 const int cur_nnz = (const int) A->nnz_in_row[i];
85
| 1 (64.5%) | 1.32 | 0.62 | 0.55 | 1.92% | 43.27% | 71.10% | 10.02% | 37.62% | 39.92% |
| 56 (63.7%) | 0.41 | 0.20 | 0.17 | 1.78% | 44.29% | 63.23% | 2.87% | 28.25% | 75.00% |
| 112 (60.1%) | 0.47 | 0.13 | 0.11 | 2.20% | 43.91% | 74.23% | 3.28% | 27.66% | 73.94% |
86 for (int j=0; j< cur_nnz; j++)
87 sum += cur_vals[j]*x[cur_inds[j]];
88 y[i] = sum;
89 }
90 return(0);
91 }